Recommendation system to Academic Congresses - a text mining application
{kind=link}
Abstract
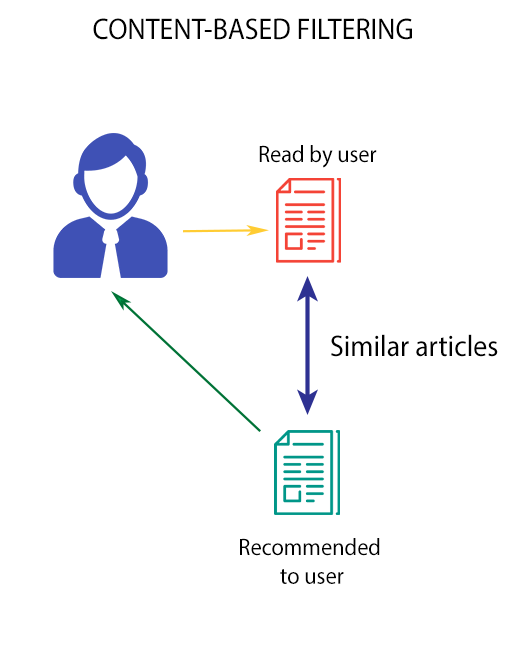
Text Mining is one of the fields of research that has been growing along with the use of machine learning techniques. The work was to develop a framework for the creation of a recommendation system using the measure of similarity and the distance between the documents of a congress in mathematics and statistics. The work can be divided into stages of preprocessing, the weighting of more important terms, reduction of the dimensionality of text terms and similarity modeling. In this work, the recommendation system was implemented for a real base, which presented 288 scientific papers over the five days and that presented the best results for the indication of a more interesting work for each participant.
Mateus Maia
Master’s Student in Statistics
My research interests include machine learning, statistical learning, ensemble methods and data-driven solutions to real world problems.