The Kernel Trick and Clustering - the Kernel K-Means method
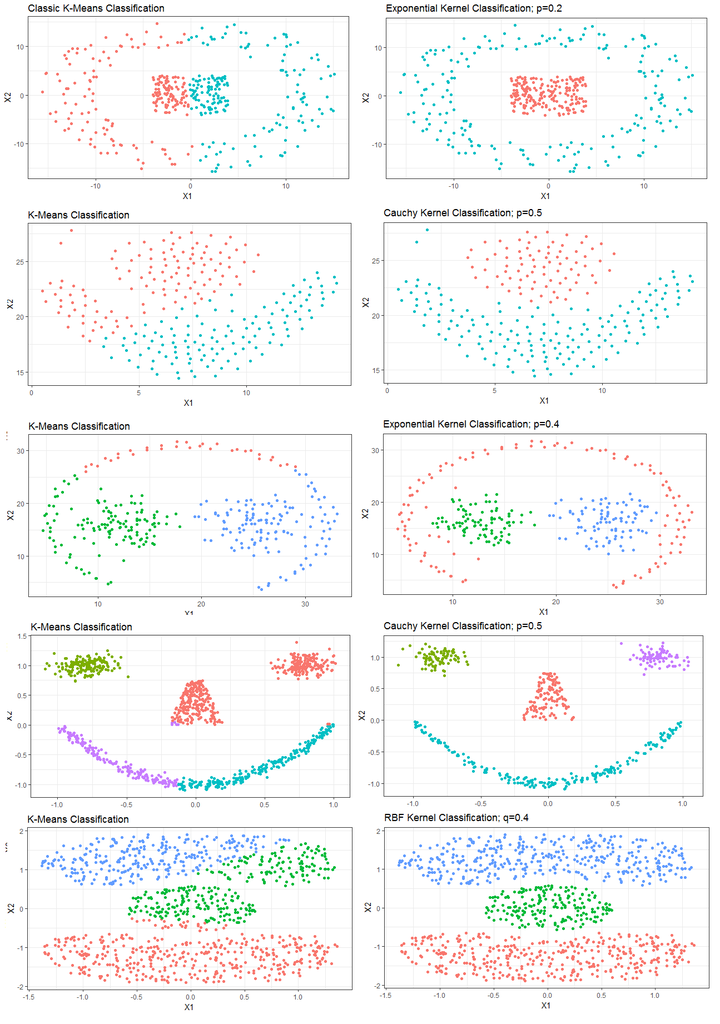 Main results apllying Kernel Trick on K-Means method
Main results apllying Kernel Trick on K-Means method
Abstract
The main objective of clustering methods is to segment the observations in subgroups or groupings, from measures of similarity between them. One of the classic examples is K-means, that Euclidean distance is used between similarity measures. However, there are some minor limitations, especially with regard to data that are not linearly separable. Kernel K-Means are as alternative to solve this problem. The methods were implemented in the R, and, as a result, it was noticed that in addition to solving well the issue of lack of linearity Kernel K-Means, is also a result of clustering when compared to classic K-Means.
Mateus Maia
Master’s Student in Statistics
My research interests include machine learning, statistical learning, ensemble methods and data-driven solutions to real world problems.