
The Random Machines algorithm is an ensemble learning method that I developed during my Master’s Thesis in Statistics at the Federal University of Bahia, under supervision of professor Dr. Anderson Ara. The main idea of this novel approach was to propose bagging proceeding using the Support Vector models as base learners, such that could provide high accuracy and diversity simultaneously, besides avoiding the necessity of applying a tuning in order to select the best kernel function to be used.
How does it work?
To provide a complete explanation about how the Random Machines estimate our model, first, we need to identify what is a bagging procedure, which was proposed by Leo Breiman (1996), and how to explore its proprieties. The bagging is based on the combination of multiple models using different bootstrap samples as training sets. The Random Machines algorithm uses the support vector model as a base learner and a random selection of the kernel function that will be used in each model over each bootstrap sample. Finally, a weighted combination of these models is made and the output y is estimated. To a complete overview of the features and characteristics of the model
Breiman when proposed the bagging procedure also showed that any model could be used as a base learning in order to compose that combination and they should be as accurate and diverse as possible simultaneously. We can define accuracy as the capacity to predict new observations. For diversity, the definition can be given as a measure of the correlation between models, or how dependent the models are among them. The figure below is from Ho, 1998, and shows an example of two different models that are completely dependent, in other others, have zero diversity since they produce the same prediction boundaries.

Image from Ho, 1998. Example of two different models completely correlated
The balance between these two features in the ensemble is a real challenge and can be an extremely difficult task. When Breiman proposed the random forest, he managed to introduce the diversity into the base models through a random subsampling of the feature space. This new approach leads to one of the most robust and famous machine learning models that we know in nowadays.
The Kernel ‘diversity’ Trick
The key idea of the Random Machines is to present a novel way of introducing the diversity in the base models, as Breiman did when published the Random Forests. However, here this low-correlation of the models will be given by a weighted random sampling of the kernel feature space. Using different kernel functions we can transform the feature space in different dimensions producing new representations. To find more details about how this sampling is made, and how its weight is assigned is important to check the original articles: Random Machines - A bagged-weighted support vector model with free kernel choice and Random Machines Regression Approach: an ensemble support vector regression model with free kernel choice for classification and regression context respectively. For an illustration of this model’s feature observe Figure 2, from the classification article that shows the different decision boundaries of using each kernel function for a simulated example, and how the combination of them through the Random Machines give a better representation of the true function.
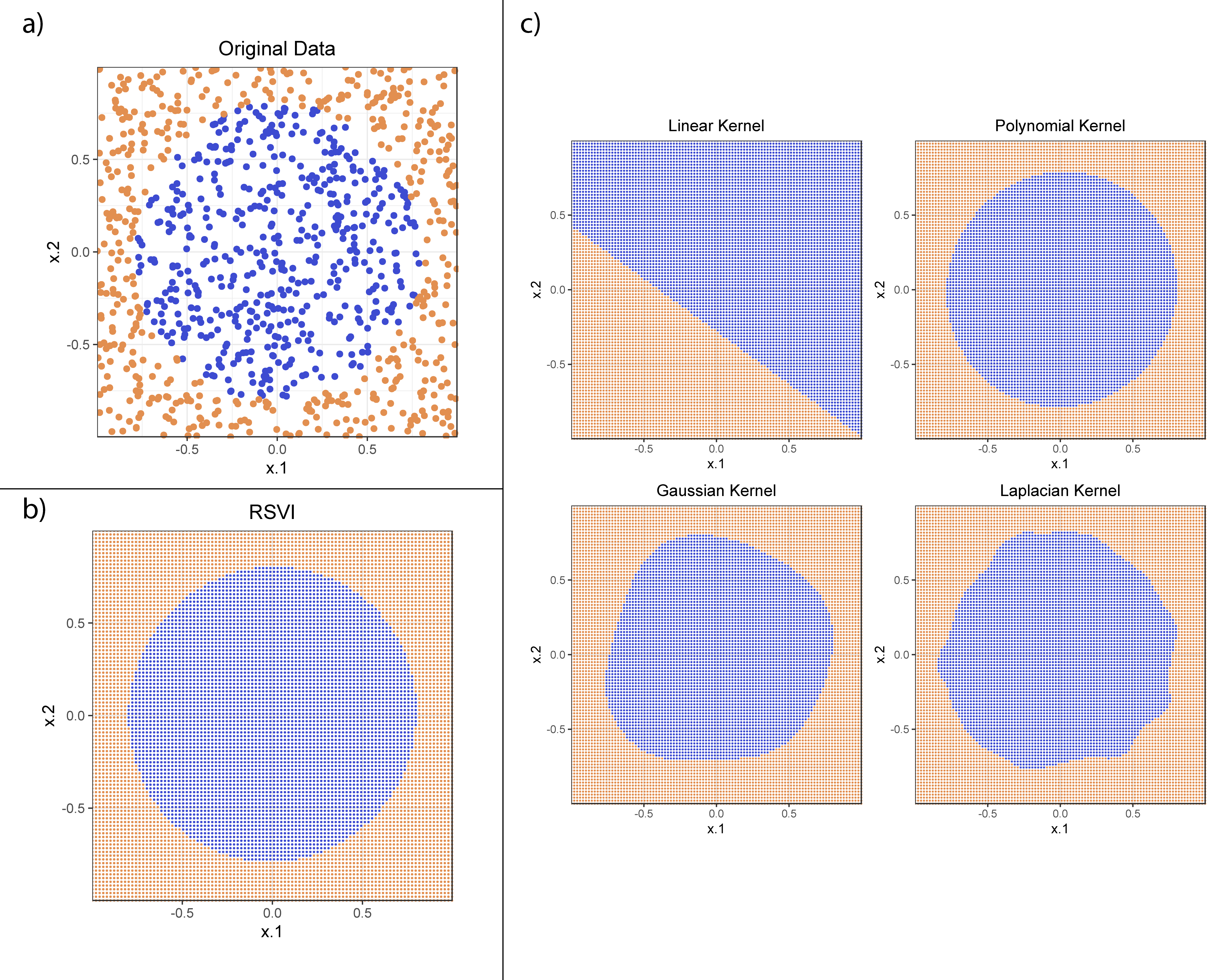
Image from Ara et al., 2020. Example of the diversity of decision regions produced by each kernel function of bootstrap models that composes the Random Machines.
The Random Machines structure
Once it’s presented how to introduce diversity through the kernel functions, is important to explain how to combine the multiple models and weigh them. Essentially, several bootstrap samples are generated and used as training data for support vector models. The probability of use each kernel function is calculated using evaluations over a test set. On the other hand, the weights used to measure the contribution of each bootstrap-model are appraised using Out-of-the-Bag samples. The Figure 3 summarizes this weighting and modeling structure for both classification and regression. The key idea of this novel proposal is that is possible to reach introduce diversity into the model through different kernels, without reducing the accuracy since the kernels that provide better predictions have more importance in the final prediction.
The rmachines package
The rmachines package is quite simple and it’s only composed of two main functions, the random_machines() that will build the model for classification tasks, and regression_random_machines() which will build a regression one. The kernlab is a dependency necessary to calculate the support vector base learners. The documentation and instructions can be found in the GitHub page: https://github.com/MateusMaiaDS/rmachines. To show how the model can produce accurate models is shown below the comparison with one of the most popular machine learning models on the community: Random Forests (2001). The databases used are two benchmarking that can be found in the UCI repository and in the MASS package, for regression and classification: stormer and clean1, respectively. The metrics to evaluate each of them were Root Mean Squared error and the Matthew’s Correlation Coefficient. The result is shown in Figure 4.
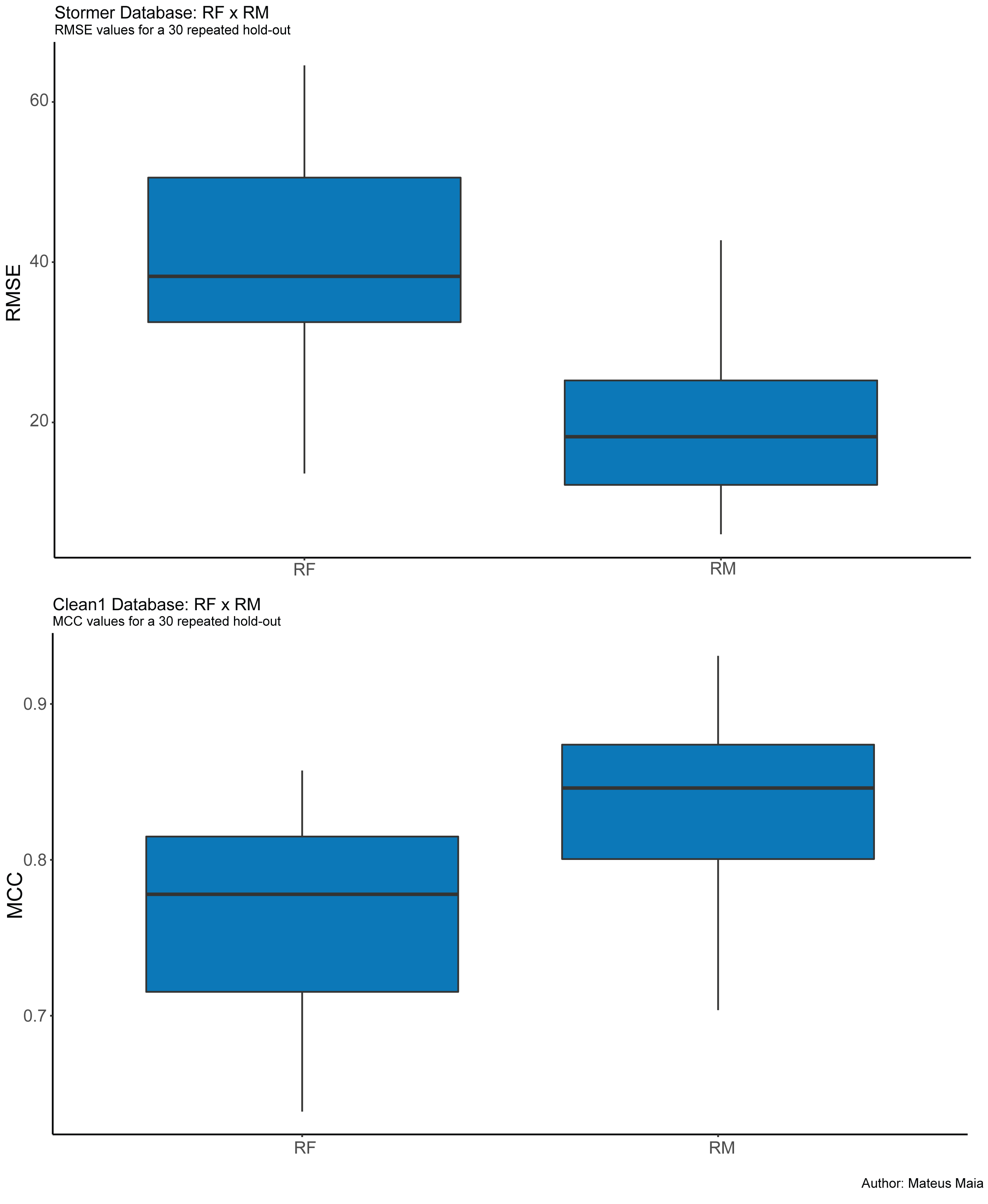
Boxplot of RMSE and MCC for compare the predictive capacity of Random Machines and Random Forests
As we can see, Random Machines showed a great performance with better predictions when compared with the traditional Random Forests.
Why not use the Random Machines model?
From the experiments that were shown in this short blog post, we could see that the proposed model, Random Machines, produced results that can achieve a great predictive capacity for classification and regression tasks. Besides it, the use of the method is pretty straightforward with the use of the presented package rmachines. Therefore, there are plenty of reasons to use it for general machine learning projects. However, Random Machines could be computationally infeasible if we consider a huge dataset, it is being realized a combination of several support vector models. Some ways to solve this problem are being studied by us (Mateus Maia and Anderson Ara), therefore if you have any idea or want to contribute to that feel free to e-mail us.